The Power & Drawbacks of Content Generation Through ChatGPT

I was looking for a fun way to learn about ChatGPT and explore it's power. As always, I like to learn through working on a project. In the beginning, it was fascinating to use it's chat and image generation features, but as an engineer, I wanted to access it programmatically so I could construct something new. This is how I ended up with creating History Snacks!
What is History Snack?
The goal of History Snacks is to simply tell you what events happened in history today. You can also switch dates to see what events happened in history on that day. It also includes an "I'm Feeling Curious" button to see the details of a random event. So basically, "snacking" on historical events instead of a 7 course meal. You can snack every day without feeling full!
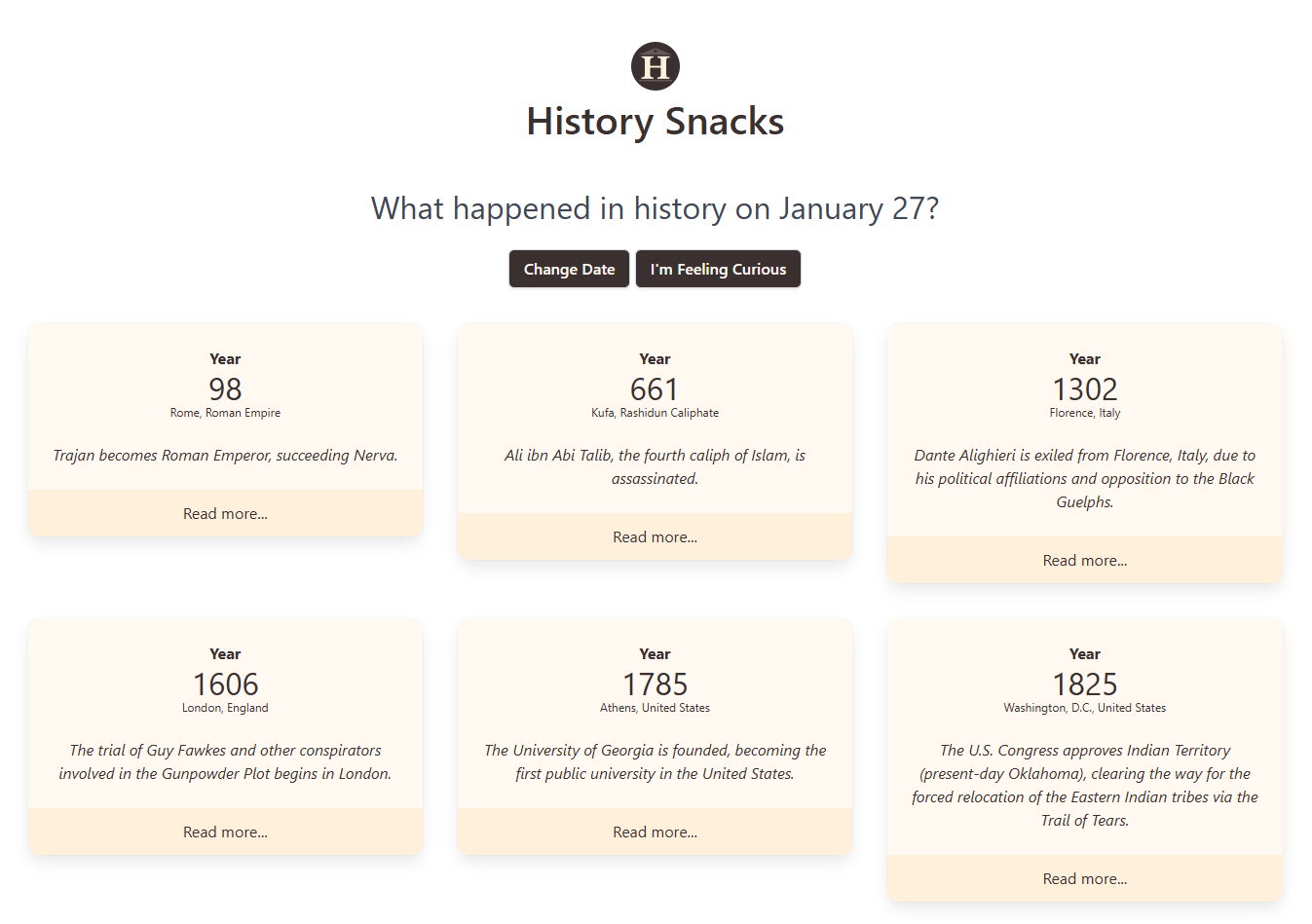
The project was envisioned with my 8 year old son who had showed interest in AI and software development. In fact, the "I'm Feeling Curious" button was his idea! He is part of all feature and UI development discussions.
This of course is not a new idea. There already are sites out there that do this including reputable names like Britannica and History.com amongst others. The challenge was if we could do this without history experts using ChatGPT.
Power of Working With ChatGPT
I'm pretty happy with the end result. I think the site is fun. I enjoy visiting on a daily basis and so does my son. Here are some of the things that actually made it possible to do this with the help of ChatGPT.
Powerful API
ChatGPT's completion API was easy to get up and running. I used Go to code the backend and hence had to write the REST interaction myself, but it was easy to get it up and running. Their tooling has gotten much better since I started.
They also have official libraries for most of the popular programing languages out there.
The ChatGPT gpt-4o Model
When I started working on this, the latest model was gpt-3.5-turbo. I was able to get good results from it, but working with gpt-4o was so much better. I was able to get a lot of metadata with each event. More importantly, I was able to get a reference URL for the source of the data for each event. I think this added volumes to the legitimacy of the data that I was getting.
ChatGPT now has a whole selection of models to choose from to reach the right balance between cost / speed & task accuracy. Details here.
Improving Accuracy & Reliability
We've all heard of various AI hallucination stories. I've also seen examples of inaccuracies, both on news and me personal queries. This was a worry for me in the beginning but then I learnt how to use the Completion API's role feature to have some control over this.
With this feature, you can actually tell ChatGPT how it should behave before answering the prompt. With this you can actually ask it to be a factually accurate history expert and only stick to factual information in a neutral tone.
For Example: A prompt with the role the system is going to play
{
"model": "gpt-4o",
"messages": [
{
"role": "system",
"content": "You are a history expert. You should deliver accurate, concise, and engaging narratives about historical occurrences, significant figures, or cultural moments, prioritizing factual correctness. It avoids speculative or non-factual accounts and stays neutral in tone, ensuring its explanations are accessible and respectful to a diverse audience."
},
{
"role": "user",
"content": "<your prompt>"
}
],
"temperature": 0.2,
}A prompt with the role the system is going to play
This along with "temperature": 0.2 reduces creativity of the responses.
Response Formats
You can use the response_format option in the completions request to get it's responses exactly as you would like (details here). This comes in very handy when using a strongly typed language such as Go.
Drawbacks of Working With ChatGPT
Although I am happy with how the History Snacks site came out, most of my time was spend dealing with the drawbacks / challenges of working with ChatGPT. Although, eventually the benefits far out weighed the costs but I encountered the following challenges.
Realtime Content Generation is Too Slow
In the beginning I thought this would be the easiest project ever. I figured I'd simply have 2 web handlers, 1 for events(/events) and 1 for the details (/event/{id}) and for each, I'd simply make a completions API call and return the response.
However, each gpt-4o call can take up to 30s! There are faster models available, but still, a modern web user will not wait 15s to see a webpage. Even if you could make it work streaming token style, it would be useless for indexing and social media sharing. Both of which will not wait 15s for a page.
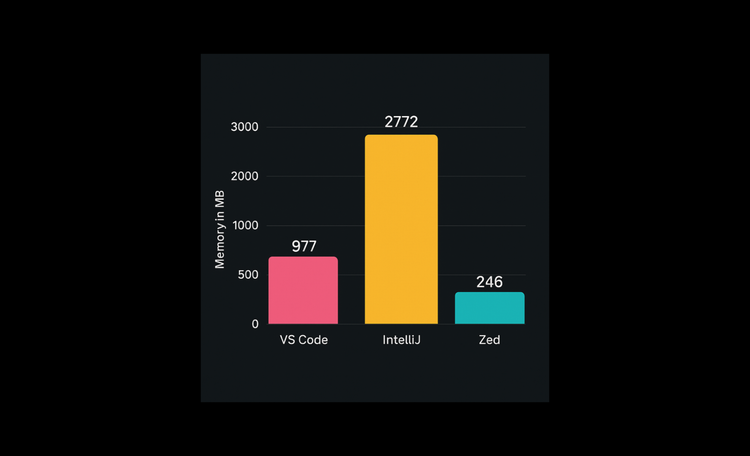
Due to this, I had to "harvest" the data offline, store it in a DB and render the site from it. This is how I got 100ms response times.
Responses to Prompts are not Idempotent
If you ask ChatGPT for a list of events e.g. on "March 23rd" multiple times, it will not respond with the exact same list every time. I thought setting "temperature": 0.2 might help with this. It certainly improves the behavior but the list of events can still be different.
To address this, the History Snacks platform has the ability to run the "Harvest" multiple times and accumulate the super set of events seen so far. However, making this work in light of duplicates has it's own challenges.
Even for events that overlap between calls, the actual text might be different. If you've asked for metadata, that might still be a little different. Due to this, the duplication detection logic needs to be a little involved and can miss things. Hence, I couldn't make the whole pipeline work without some manual work involved.
Prompt Engineering (more of a personal drawback)
The quality of the responses depend heavily on the quality of your prompts. I couldn't help but feel it was more of art than a science. There was a lot of trial and error involved and you're still always left with a feeling that you can do better.
For an old school engineer like me, this was a little unnatural. It's a little ironic. I feel engineers choose their paths because engineering has simpler mechanics and is more deterministic than human nature. Now, we're making engineering more human!
This also basically means you have to spend $$ to get it right.
Cost?
I'm not sure if this is a real drawback. It wasn't for me personally. The only reason I mention it here is just the plain fact that it's there. To get the project to where I was happy with, I had spent close to $100 in trial and error. On the other hand, since all the data is now cached, it doesn't really cost much to keep it alive. Nonetheless, I have to keep on running the "harvesting" pipeline regularly just in case ChatGPT responds with a new event but this incremental cost shouldn't be that huge.
However, given that all the other tech that I used in this project was practically free and that hosting fees for a small project like this would probably be cost of a decent burger per month, $100 to get it up and running might be and important fact for someone.
Conclusion
I thoroughly enjoyed working on this project and the output ended up being as good as I was hoping it to be. I got a chance to really learn about the nuances behind the LLM era of AI and I love solving technical challenges.
For me, the $100 spent was well worth it. LLMs are fun and interesting and I really enjoyed working with ChatGPT's version of the technology. Can't wait to try it again in another project.
I started the History Snacks project with a lot of skepticism. I felt us real engineers can't be replaced, but I had to see and experience it for myself. Now, I'm not too sure!


Comments ()